
Big AI providers, like OpenAI and Anthropic, develop and adjust their models based on their business objectives. While the advancement of AI is the core objective, profit-seeking and industry dominance are always there, changing how these companies provide their products and services.
This is great if you're a happy ChatGPT Plus user enjoying moderate usage. But for bigger companies with thousands of daily requests from internal tools, people with specialized projects, or anyone building the next market-changing product, big AI companies can be restrictive. The closed source model offers limited customization and the token costs can add up quickly—especially when using the best AI models.
But is the future of AI closed source? DeepSeek's R1 shows the game is on for open source projects, where technology is shared for free, runs outside the black box, and offers more customization. In line with this open future, Hugging Face is a key instrument to make collaboration, iteration, and open source model releases a reality.
After all, there's a reason Google said "we have no moat, and neither does OpenAI."
Table of contents:
What is Hugging Face?

Hugging Face is an online platform dedicated to data science and machine learning. You can browse datasets, train AI models, share your work, and collaborate with others as you do so.
Beyond advanced learning resources and community features, it offers the transformer library: a collection of ready-to-use APIs for all AI models on the platform, easily accessible by writing a few lines of code. This is one of its most important features: it speeds up development dramatically.
Originally launched as a chatbot app for teenagers in 2017, it's a testimony of how much—and how far—a product can pivot to achieve product-market fit.
How to use Hugging Face
Hugging Face offers a lot, catering to a wide audience. Here's how some folks are using it:
Researchers advancing the state of AI and machine learning manage their work with Hugging Face, as it offers all the tools to train, host, and test models. They can also showcase their results here and invite collaboration from other teams.
Data scientists can create and browse datasets. When creating, they collect the highest-quality data for a specific use case, labeling it to help AI models train on it. When browsing, they're looking for existing datasets they could use to train or fine-tune an existing model.
Machine learning engineers and developers take advantage of the transformers library to easily build AI solutions using the platform, as well as to share the work they're doing with others.
Educators and students can access learning resources and leverage the community features to learn, get hands-on experience, and connect with others to start projects.
Business professionals browse the model collection to find high-quality models that can match or outperform the main providers like OpenAI, or that are more specialized for tasks like sentiment analysis or computer vision. Since these models can be hosted on Hugging Face on a compute-per-hour pricing, they may be hunting for cost savings while maintaining quality.
AI enthusiasts pop by to browse demos and take a look at the most popular models to see how the technology is evolving.
Pick a collection of datasets

A dataset is a collection of data used to train, validate, and test AI models—a fundamental base for machine learning. Datasets are composed of examples, the data points the model will learn from, and labels, the desired output when the model encounters the corresponding example.
As a model trains on a dataset, it will start understanding the relationship between examples and labels, identifying the underlying patterns. After the training process is complete, you can prompt it with data it hasn't seen before, and it will give you an answer based on the patterns it saw.
Creating a high-quality dataset is hard and time-consuming, as the data needs to be a useful and accurate representation of the real world. If it isn't, the model may hallucinate more often or produce unintended results.
Hugging Face hosts over 30,000 datasets you can feed into your models, making it easier to get started. And, since it's an open source community, you can also contribute with your datasets and browse new, better ones as they're released.
What do Hugging Face datasets look like? I took a quick tour, and here are a few notable ones:
wikipedia contains labeled Wikipedia data, so you can train your models on the entirety of Wikipedia content.
openai_humaneval contains Python code handwritten by humans, including 164 programming problems, which is good to train AI models to generate code.
diffusiondb packs in 14 million labeled image examples, helping AI text-to-image models become more skillful at creating images from text prompts.
Showcase your work in Spaces

Hugging Face's Spaces is where you share your work with the community. You can create showcases and small apps, plug your AI models into them, and add instructions or project information. Anyone can then visit your Space and see what you created: in the image above, you can see a Space hosting a model that can edit images based on a text prompt.
The platform provides the basic computing resources to run the demo (16 GB of RAM, 2 CPU cores, and 50 GB of disk space), and you can upgrade the hardware if you want it to run better and faster.
The best part here is that many Spaces don't require any technical skills to use, so anyone can jump straight in and use these models for work (or for fun, I don't judge).
Try a selection of chat models in the Playground

Hugging Face created a Playground where you can test a selection of the available LLMs. While this chat app doesn't have as many features as ChatGPT, it can give you a good feel of the quality of each model—so you can then choose whether you want to build with it.
You can try model families such as Google's Gemma, the small language model Microsoft Phi, and even DeepSeek's R1.
Use HuggingChat, a ChatGPT alternative

While the Playground is the best for prompt engineering and testing models, HuggingChat is closer to a true ChatGPT alternative. It has all the basic features of an AI chatbot, providing free interaction with the most popular open source models.
Learn about AI and machine learning
Hugging Face compiles a range of (highly technical) learning resources on advanced topics such as natural language processing (NLP), deep reinforcement learning, and even machine learning for games.
These guides aren't meant for non-technical people. They're better suited for developers looking to get a better understanding of how Hugging Face, AI, and machine learning technology work in-depth.
The best Hugging Face Spaces
Hugging Face Spaces are evolving a little bit every day as new projects are released. Here are a few interesting ones to try out:
GFPGAN: Practical Face Restoration Algorithm restores old photos and improves definition for AI-generated faces.
Chat with an Image lets you ask questions about an uploaded image.
Audio separator extracts vocals from background music.
CLIP Interrogator helps you find the text prompt for any image, so you can do some prompt engineering for image generation.
OpenAI Whisper can be used for speech recognition, translation, and language identification.
Hugging Face alternatives
Hugging Face focuses on open source collaboration, doubling as a productivity and hosting platform for AI and machine learning. But there are other platforms out there for using community models or tuning flagship ones.
Replicate is another community-driven platform that hosts varied open source AI models, fine-tuned for multiple use cases. You can easily start using any of them by calling their API and integrating the outputs into your app, in a similar way to Hugging Face.
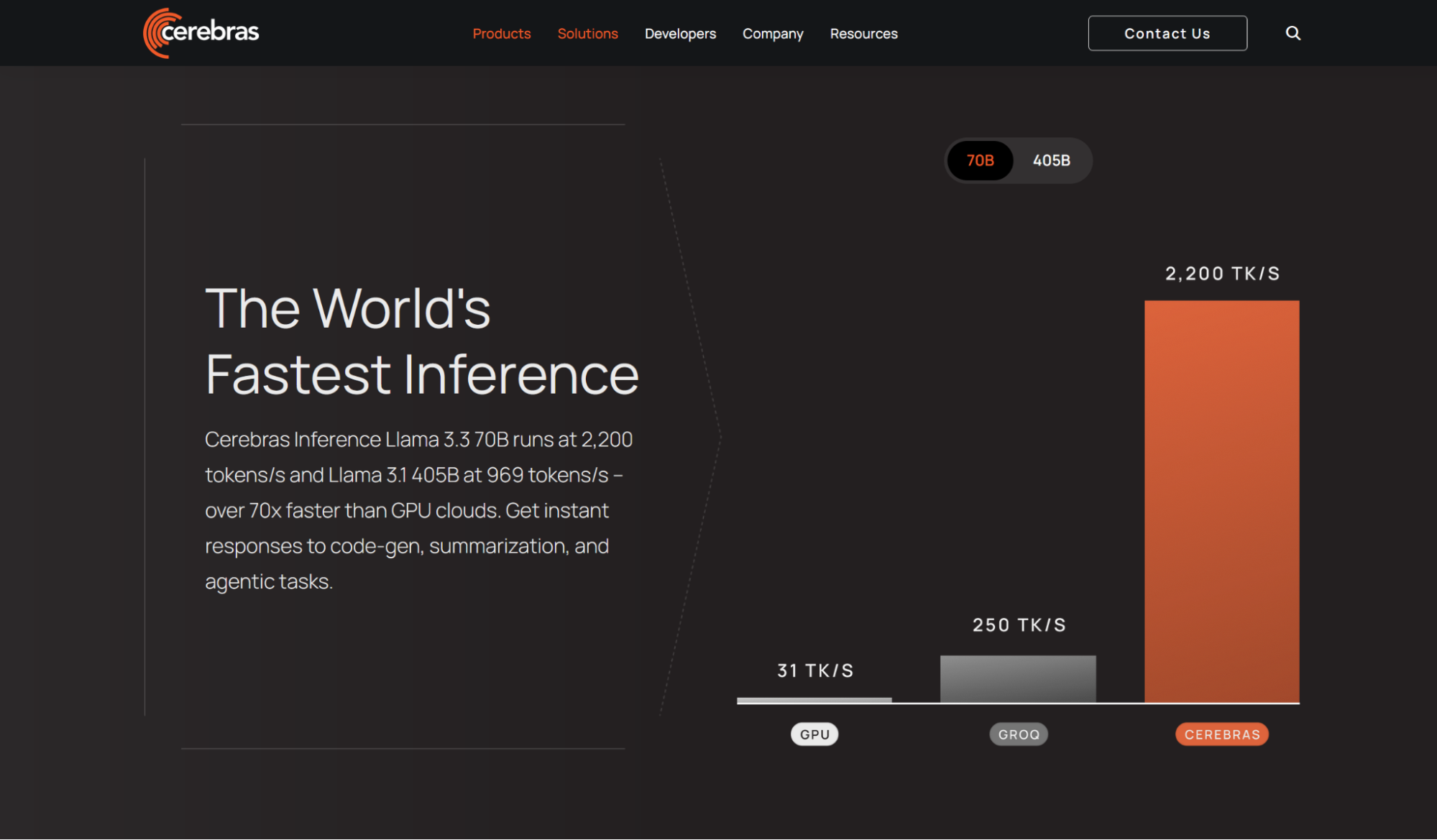
Need to train a model from scratch or run it at an extremely high speed? For advanced uses or time-sensitive apps, platforms like Cerebras, Groq and Together AI offer services for custom deployment of open source models.
Beyond these, the giant cloud computing companies have their AI infrastructure platforms. Microsoft has Azure AI Foundry, Google has Vertex AI, and Amazon Web Services has Bedrock.




While each platform has its differences—one noticeable one is model availability—you can deploy leading AI models, fine-tune them, and manage performance and costs from a centralized dashboard. These are developer-grade, although adventurous non-technical users could learn how to deploy and run models, too.
Guide to using the Hugging Face API, no-code required
Don't know how to use Python but still want to connect open source models into your apps? If you know how to work with APIs, you can use a no-code app builder or an internal tool builder to run Hugging Face models.
In this guide, I'll walk you through every step, from getting an access token to making your first call. I'll be using Postman, an API development platform commonly used to test API endpoints.
Getting an access token (API key)
Once you create a free Hugging Face account and land on the dashboard, here's how to get your Hugging Face API key:
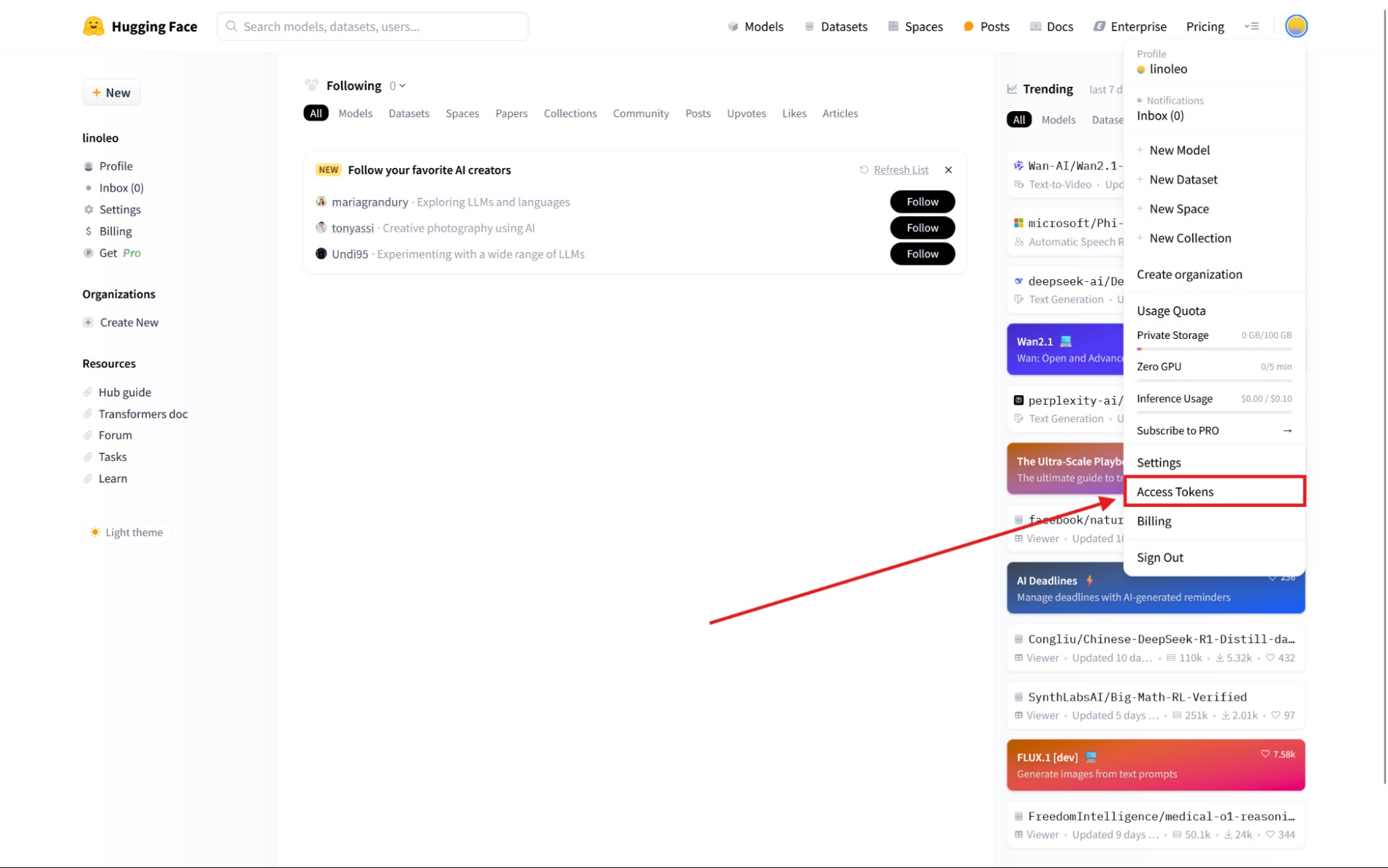
Click your profile picture at the top right of the screen, and then click Access Tokens.
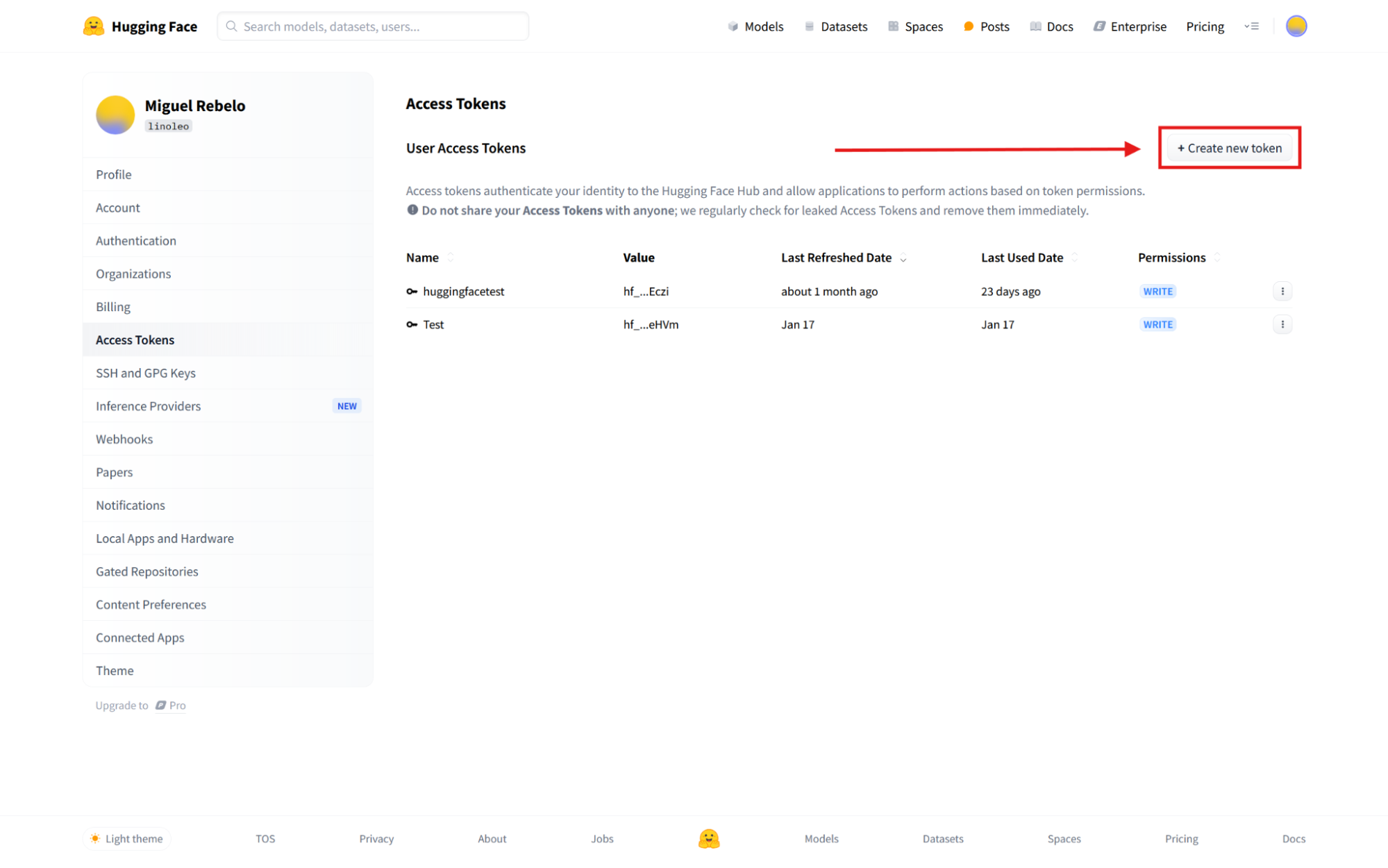
Click the Create new token button.
The next screen lists all the token's permissions, determining the access someone using it will have. For this tutorial, click the Write tab: this will give this token full permissions. (Important note: In general, giving full permissions is risky and unnecessary. When you're ready to launch your app, adjust the permission levels for the least number of privileges required to run all the core features.)
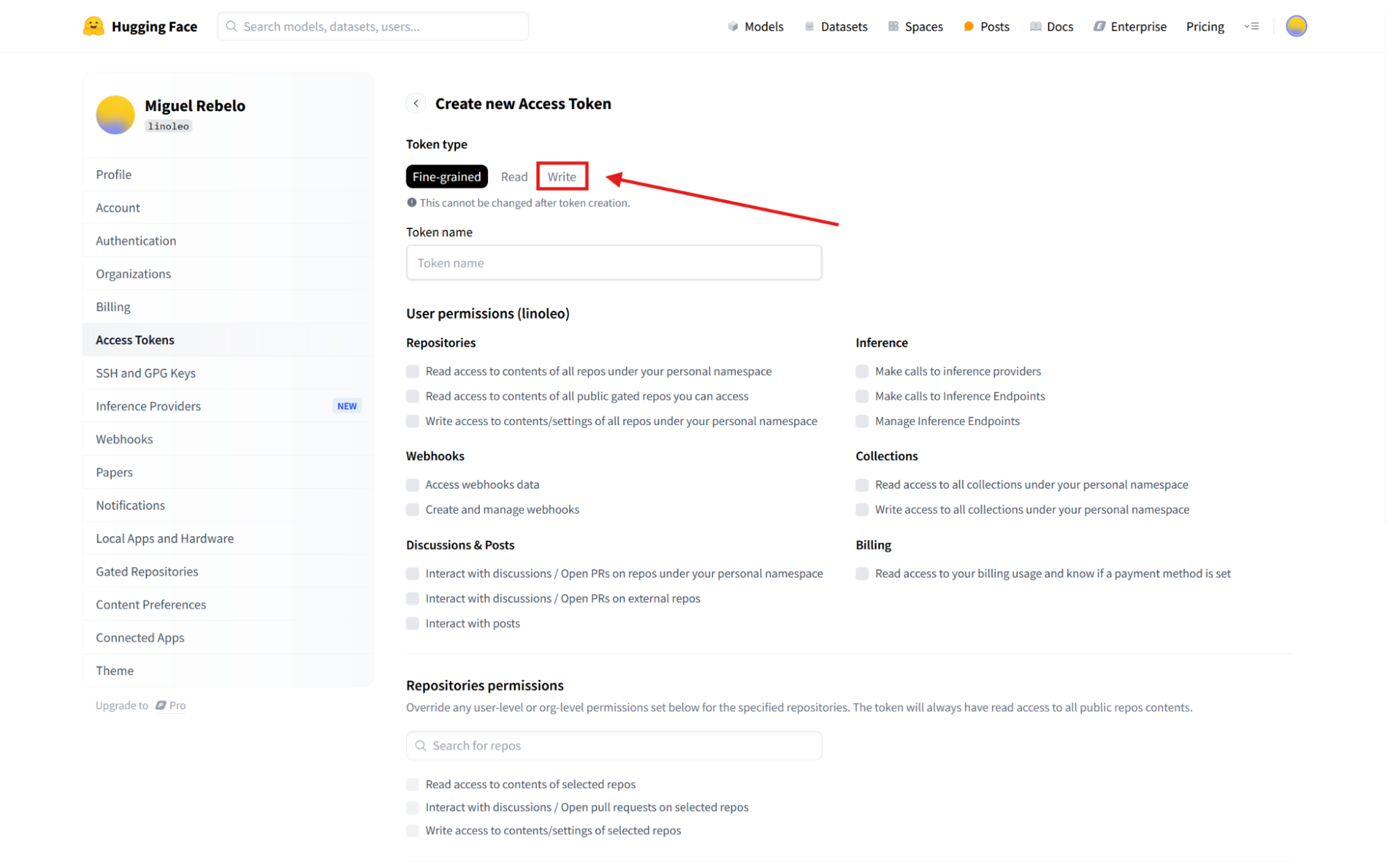
Name the token
testhuggingface(or something more catchy of your choice) and click Create token to continue. This will generate a new access token, also known as an API key. This identifies you with Hugging Face, handling access to models and deducting credits from your account, so keep this key safe at all times.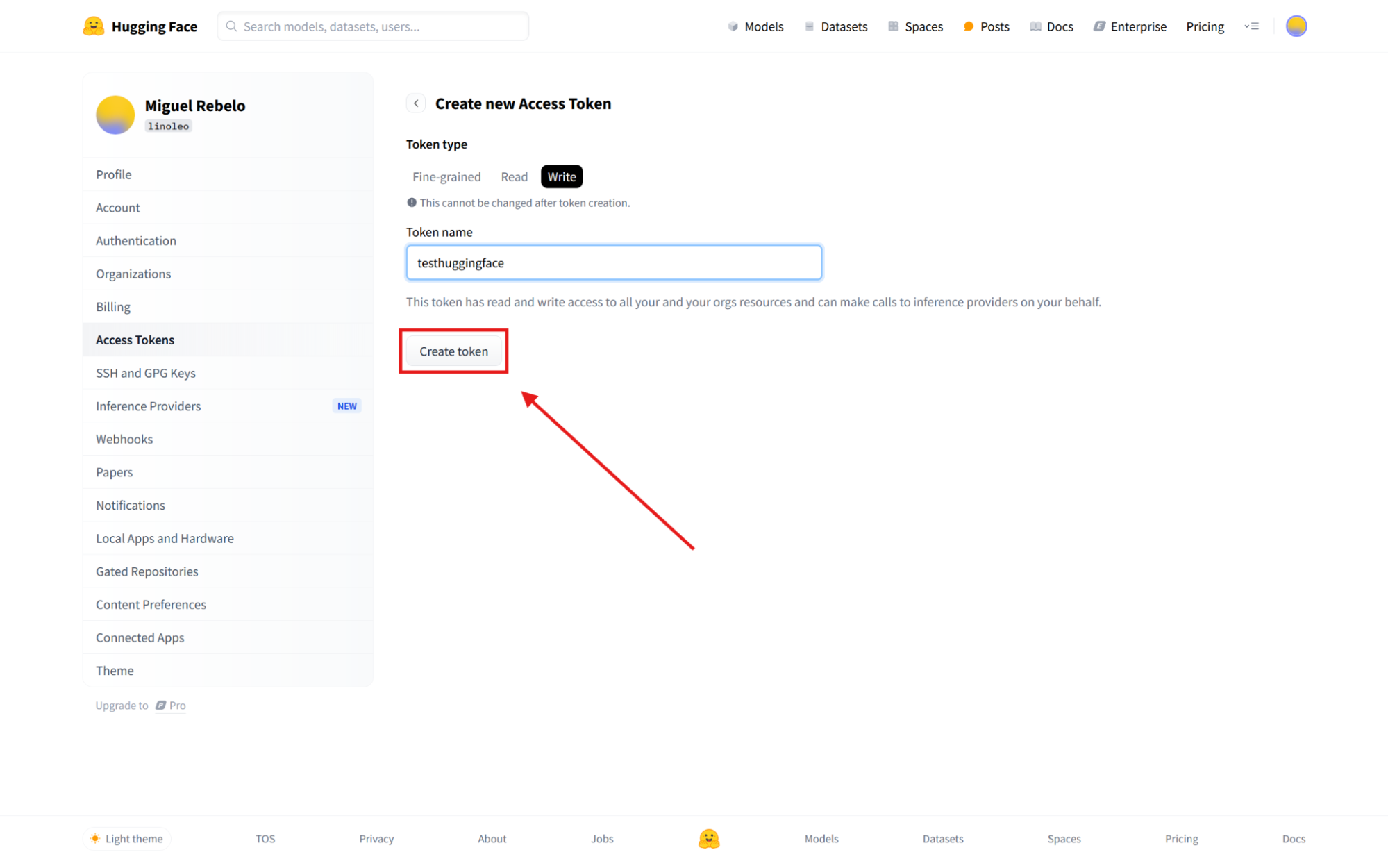
Copy the access token and store it in a safe place. Once you close this pop-up, it won't appear again. But don't worry, you can always invalidate this token and generate a new one whenever you need to.
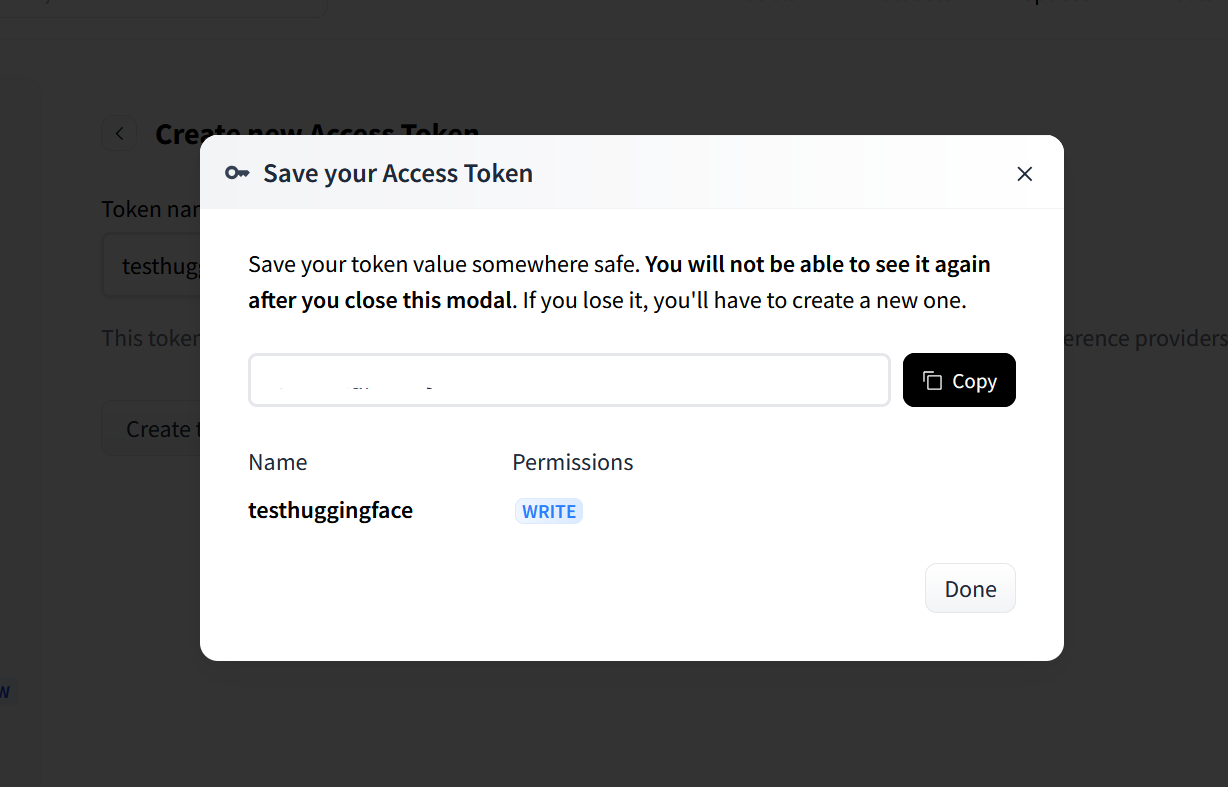





Another important note: Never paste your API key into code or a file that can be read online. Search Google for API security best practices, and set up adequate environment variables to prevent others from using it.
Selecting a model
Let's find a cool model.
Click the Models link at the top of the screen.
DeepSeek is popular right now, so click the deepseek-ai/DeepSeek-R1 model to open the details page. If you can't see it, type the model's name in the input labeled Filter by name at the top of the list.
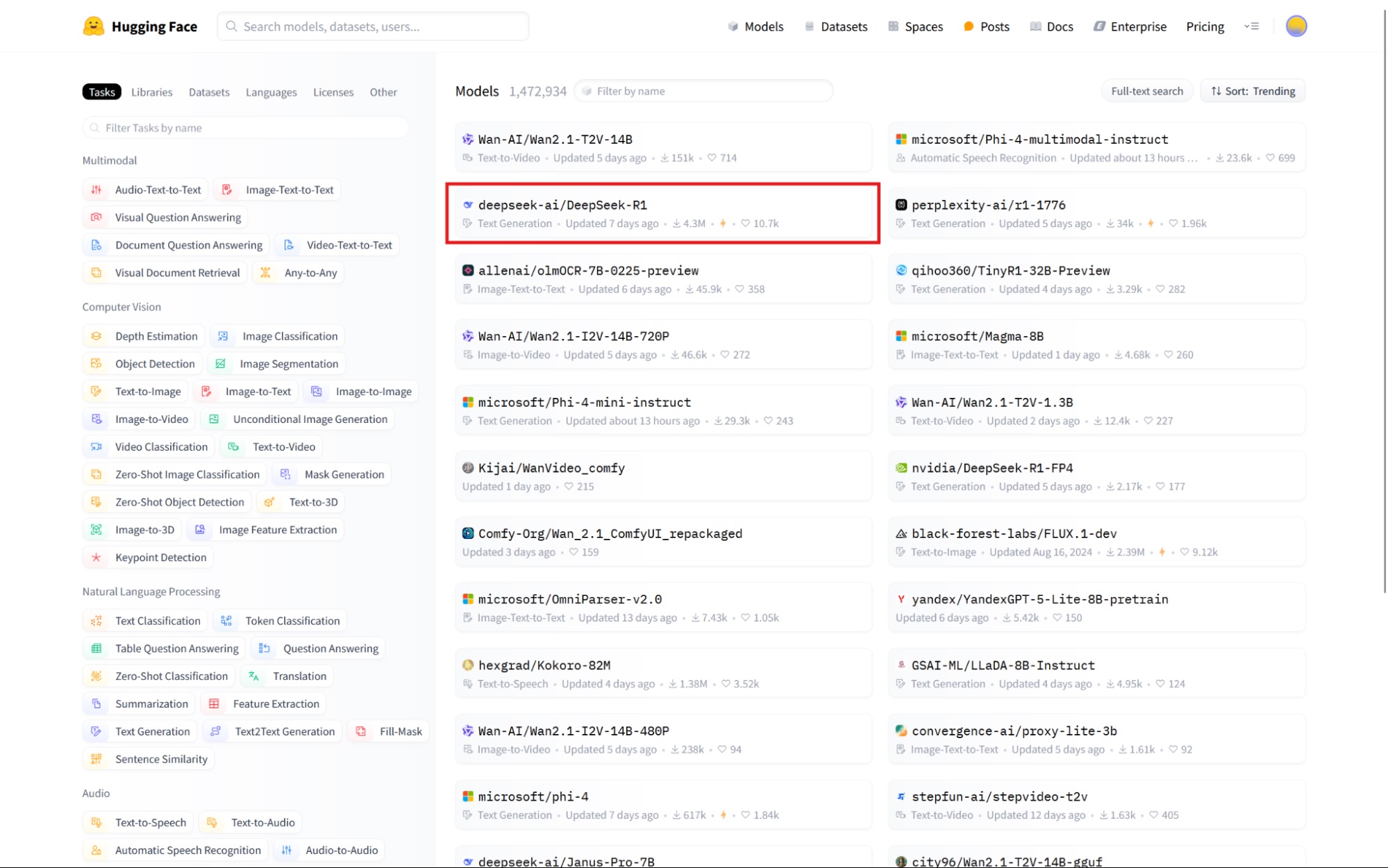
There's a lot of information here, so let's go slowly. On the left side, you can read a description of the project. On the right, you can see stats for this project and even test the model on this page: use the Inference Providers box to do so.
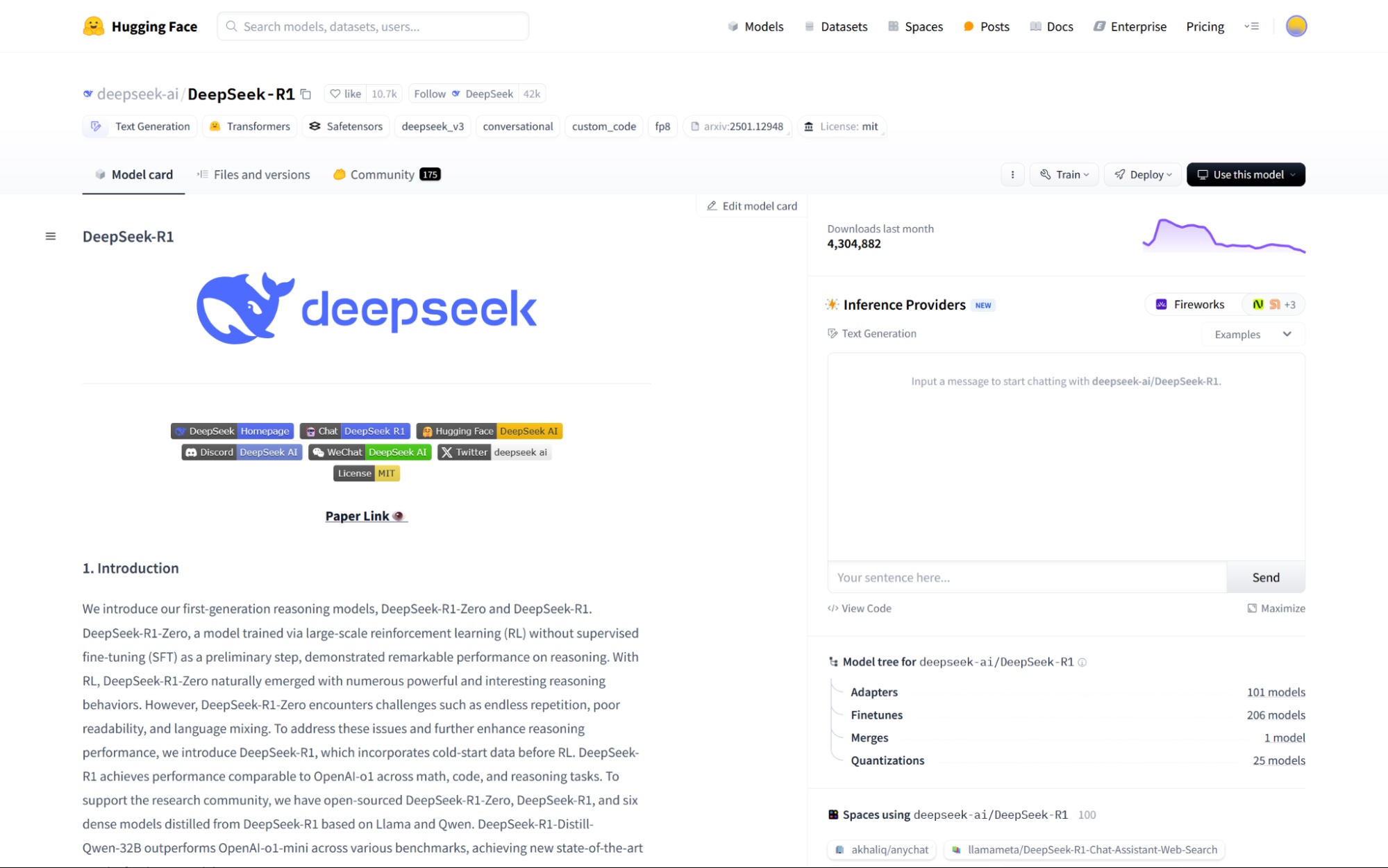
We want to deploy this model to use it with an external platform. Click the Deploy dropdown.
Click Inference Providers to continue.
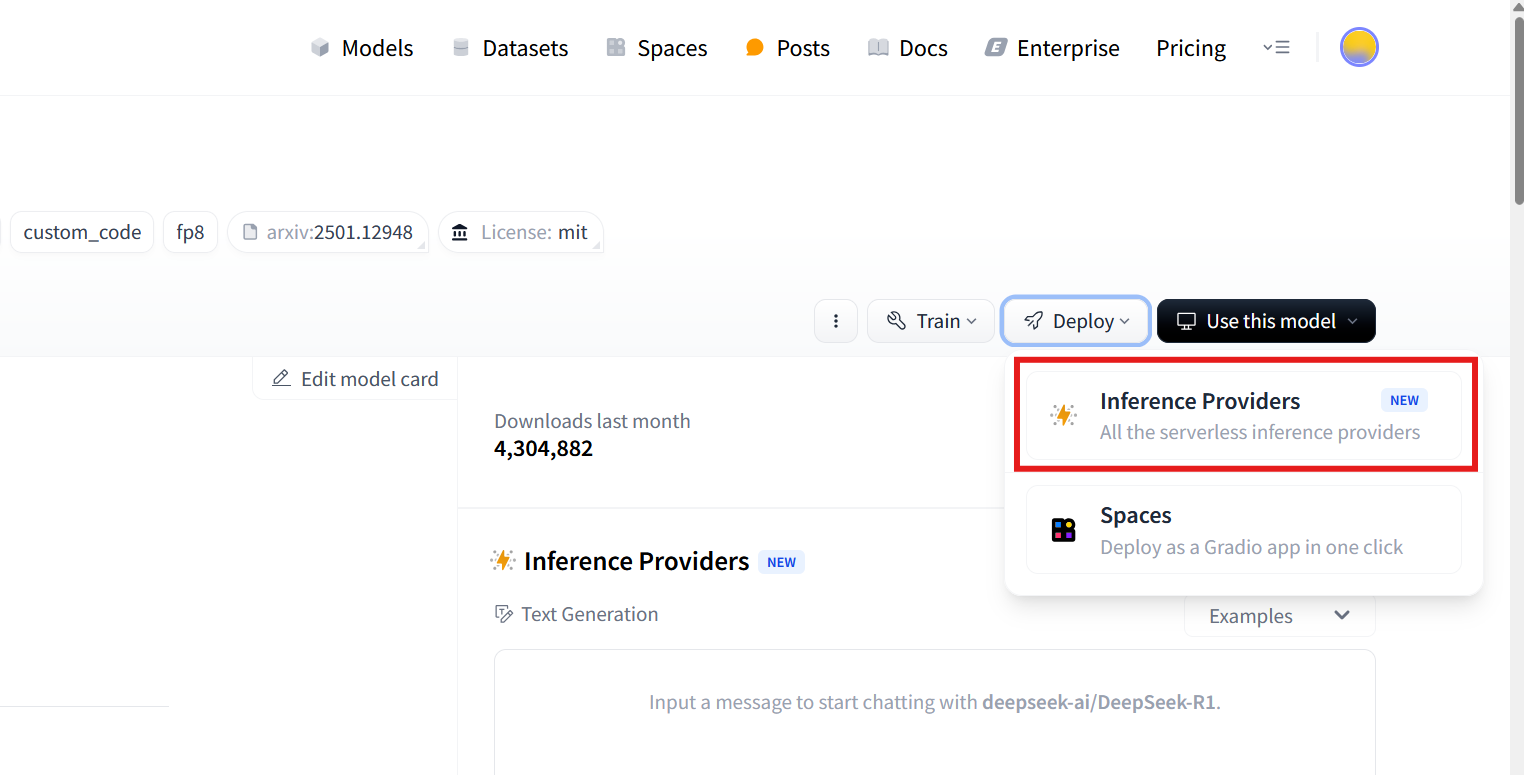
A pop-up appears with the code required to deploy this model. We'll use the Together AI deployment, so select that at the top. According to the documentation, this is a secure deployment of this model: your data isn't routed or shared with China at any time.
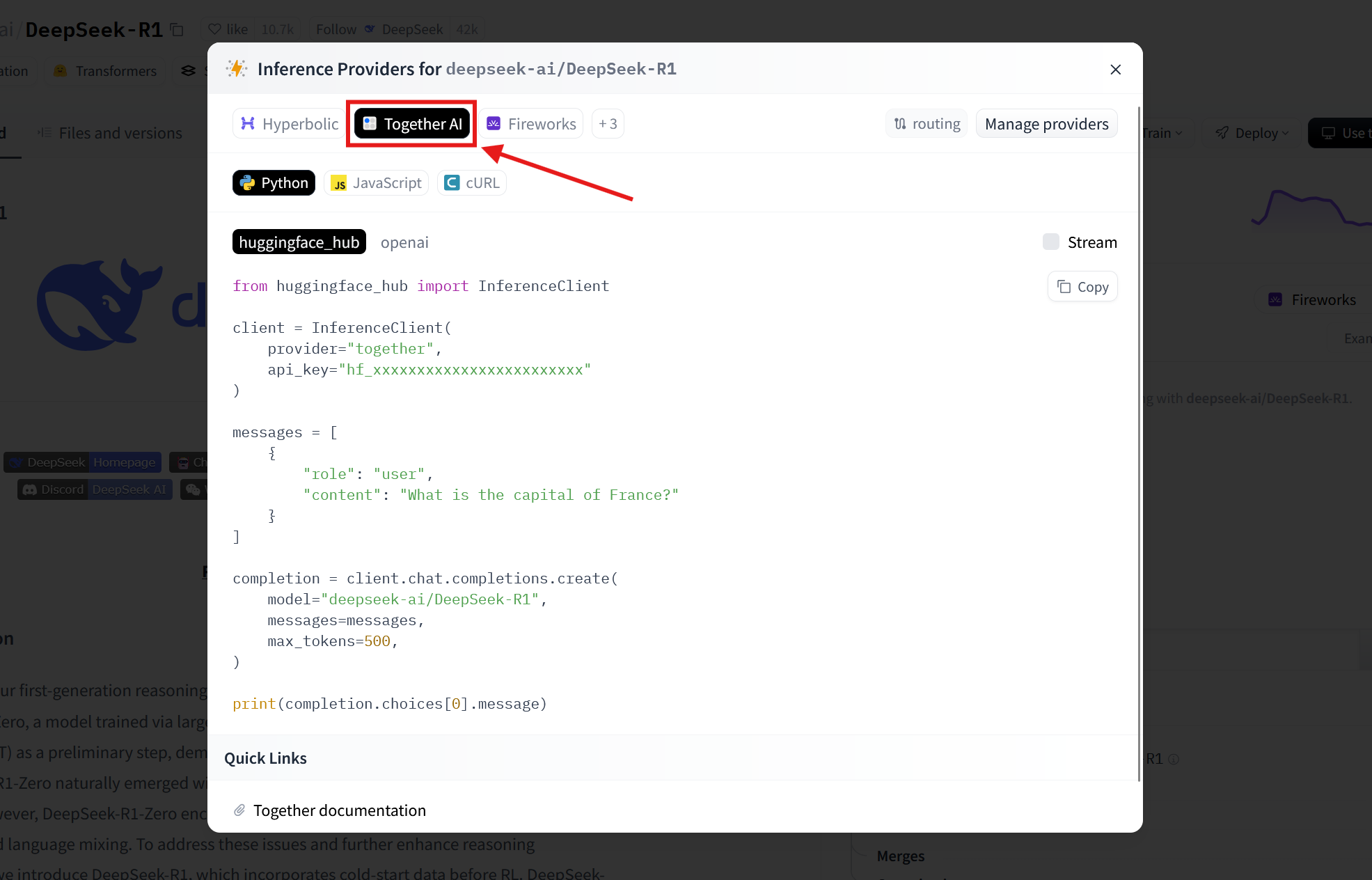






Note: Available providers may vary over time. If you don't see Together AI in the first few options, click the +3 pill next to the provider names. This will reveal the rest of the list.
Getting the call details
Let's gather the information we need to set up the call.
Click the cURL button.
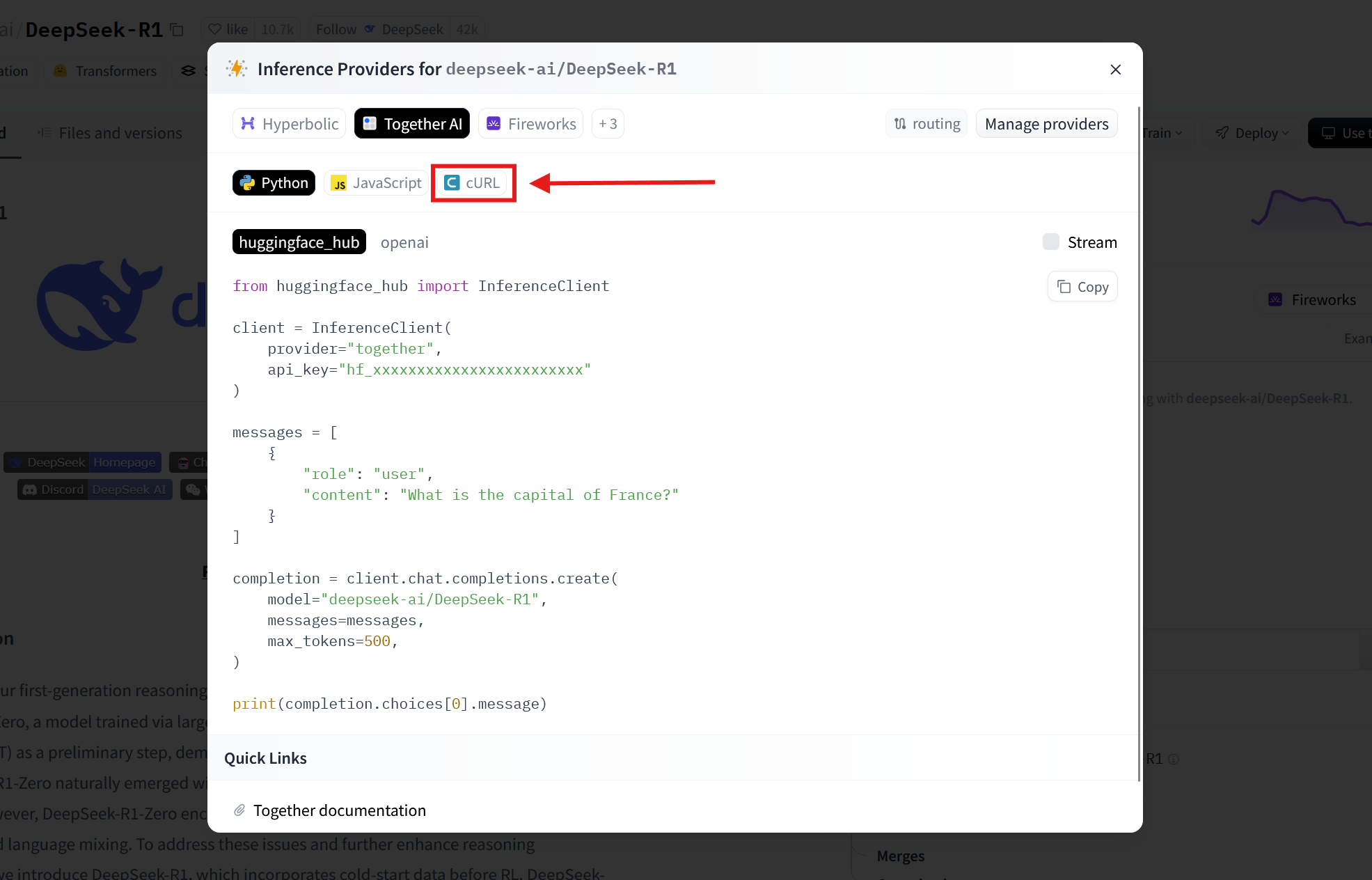
This reveals the command line instructions to run the call from a server terminal.
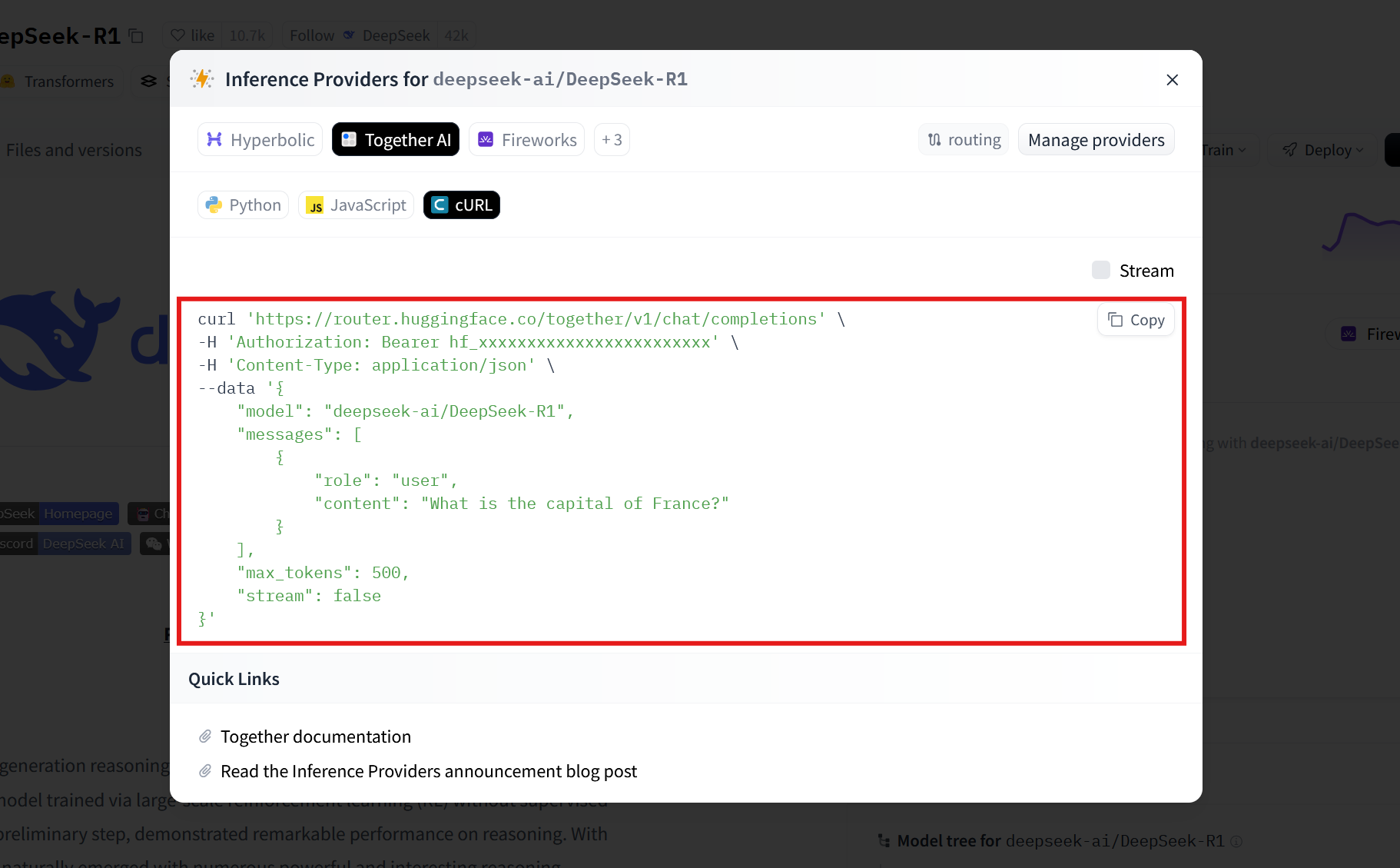


The curl at the start is the terminal command that starts the protocol. This calls the URL where DeepSeek is hosted. The backslash (\) at the end has no technical effect: it's only there to make it readable for you and me.
curl 'https://huggingface.co/api/inference-proxy/together/v1/chat/completions' \
API calls have headers that tell the server how to handle the request, marked by the -H flag.
The first flag is Authorization: this is where your API key will have to be pasted, authenticating you with the server. Without this element, Hugging Face doesn't know who's calling and it can't apply your settings. The string of x characters marks where you'll have to paste your key.
-H 'Authorization: Bearer hf_xxxxxxxxxxxxxxxxxxxxxxxx' \
The second flag is Content-Type: application/json. This tells the server what type of data it'll find in the request body.
-H 'Content-Type: application/json' \
Next up is the data flag. This is the actual data passed on to the server.
--data '{
"model": "deepseek-ai/DeepSeek-R1",
"messages": [
{
"role": "user",
"content": "What is the capital of France?"
}
],
"max_tokens": 500,
"stream": false
}'
Let's break it down line by line. The model key/value pair identifies which model we want to use, out of Hugging Face's vast library.
"model": "deepseek-ai/DeepSeek-R1",
Next, an array of messages. This contains two keys:
"role" determines who is sending the message. The "role" key indicates who's sending the message. Possible values include
"user","assistant", or"bot"."content" is the content of the prompt the user is sending. Editing this with other text is the equivalent of writing a new prompt in the ChatGPT input window.
"messages": [
{
"role": "user",
"content": "What is the capital of France?"
}
],
"Max tokens" determines the maximum number of tokens generated in the response. Use this to limit the model's output. It accepts only numbers; notice these don't have to be enclosed in quotes.
"max_tokens": 500,
Lastly, the "stream" key configures where the model will send the output token by token (as a stream) or generate the response fully and send it in one go. It's a boolean type (with two possible values: true or false), so let's leave it false, as streaming is harder to set up.
"stream": false
Setting up the call in Postman
We'll use Postman as an example, but if you want to build this functionality into your apps, you can read the documentation on how to set up API connections in your favorite app builder. Here are the API documentation pages for Bubble, FlutterFlow, and Glide.
Once you create an account and log in, click New request at the top of the screen.
Remember the URL at the start of the cURL command?
https://huggingface.co/api/inference-proxy/together/v1/chat/completionsCopy and paste it into the main input field on the right side of the screen.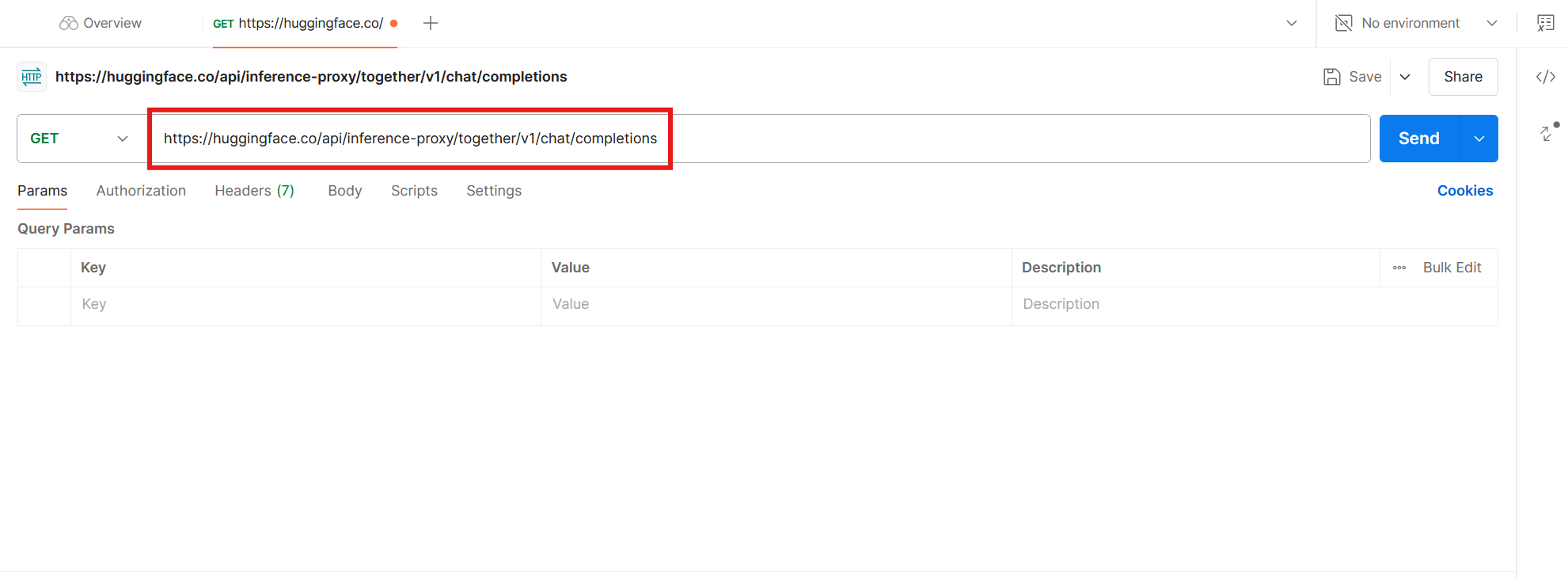
The call type isn't specified on the Hugging Face project page, but it's safe to assume it'll be POST: this is the HTTP method for calls where we're sending data to the server.
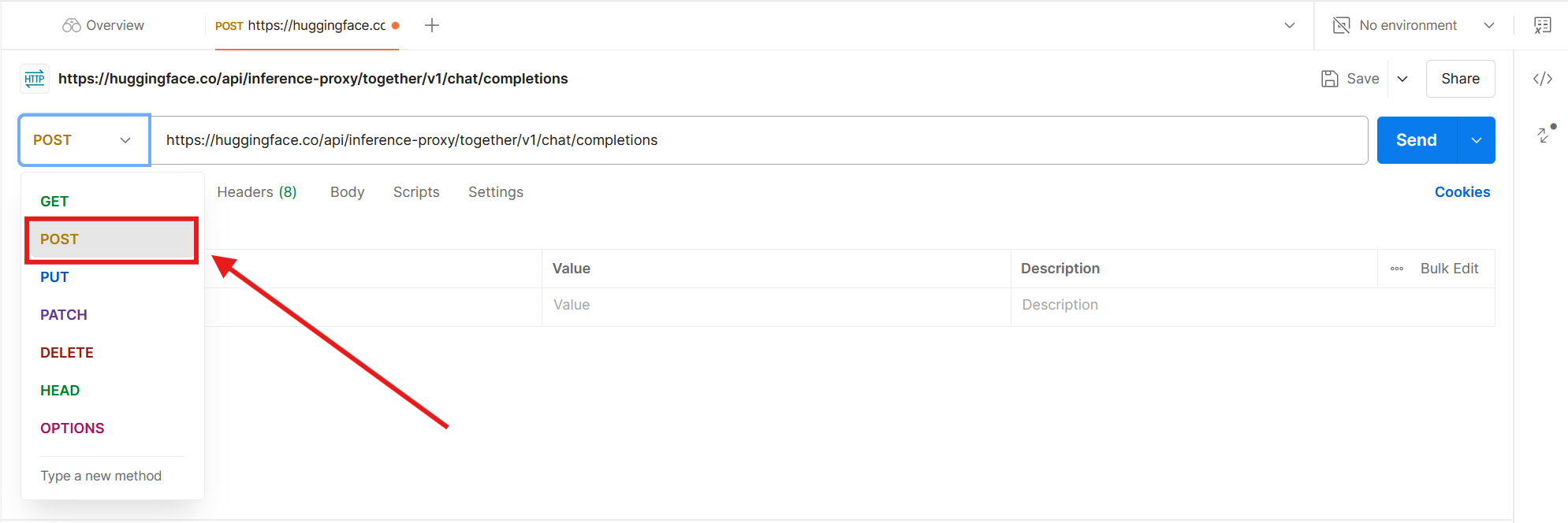
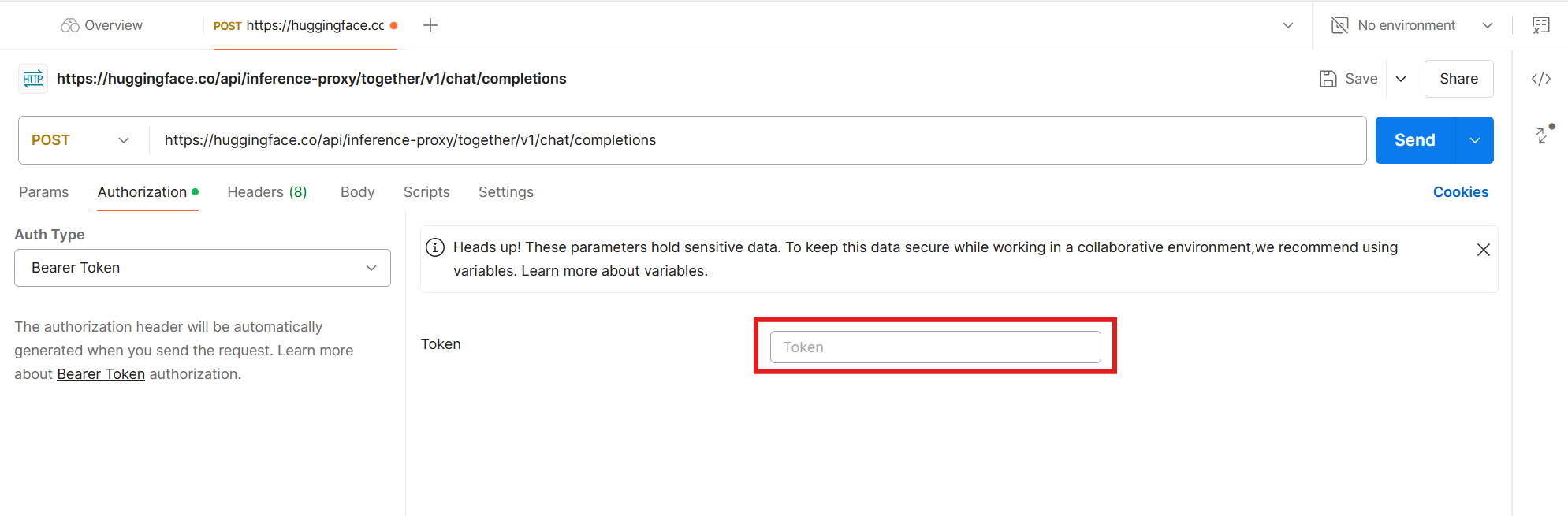
Instead of using the Authorization header, Postman has a dedicated tab where we'll post our Hugging Face access token. Click Authorization.
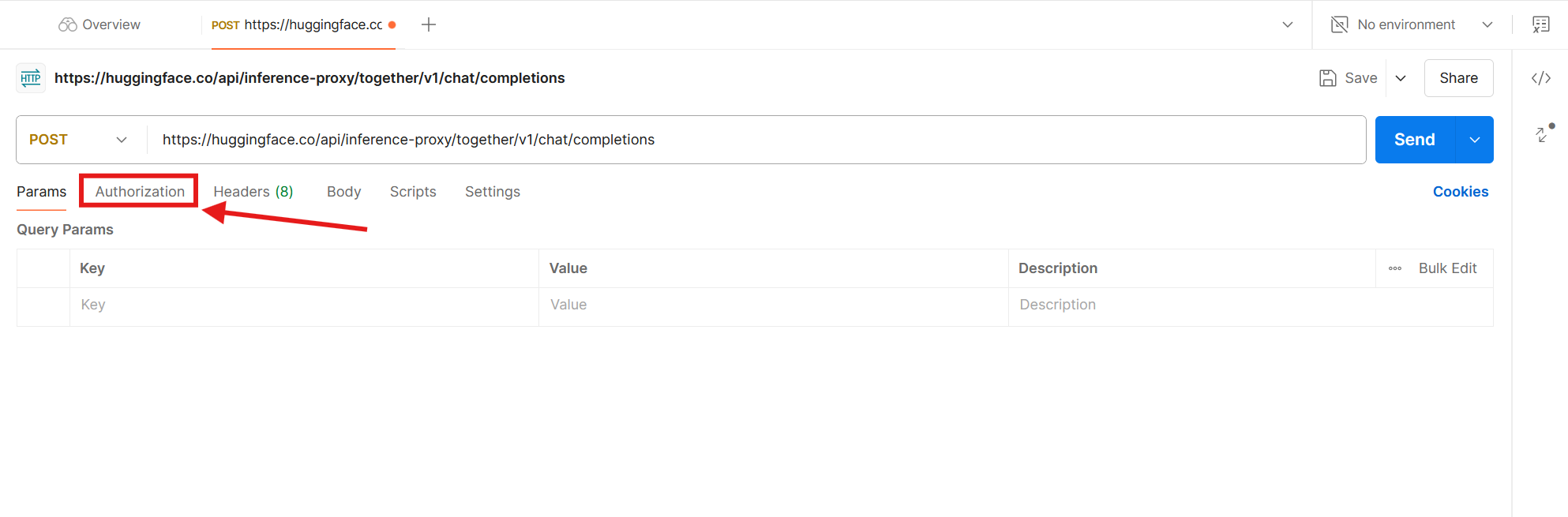
Click the dropdown, and select Bearer Token. This matches the type set by Hugging Face. Each API has its specific authentication type, which you can read more about in the documentation.
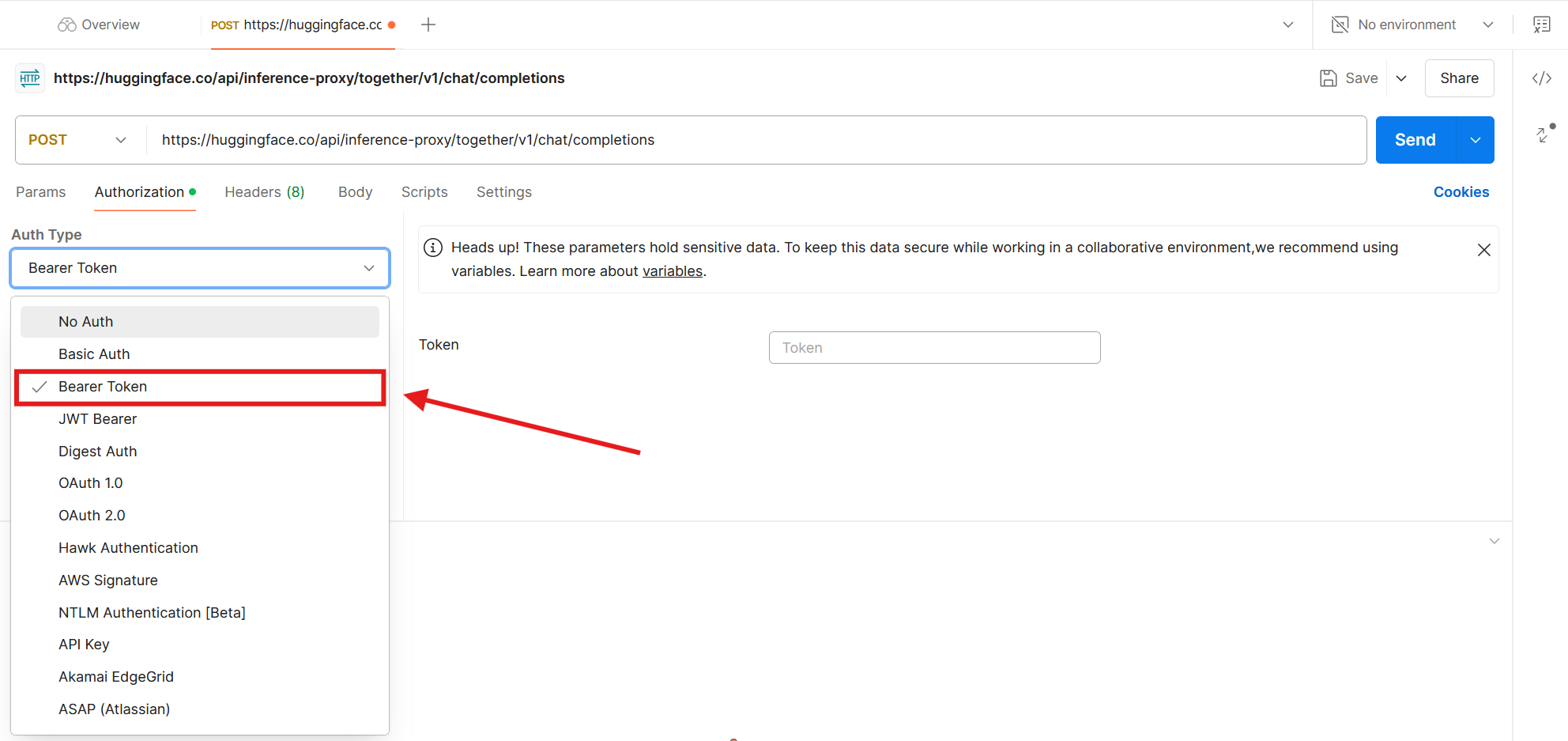
Copy and paste the Hugging Face access token (API key) you generated earlier into the input field.
Next, it's time to paste the body of the API call: this is everything in the data flag we explored earlier. Click Body.
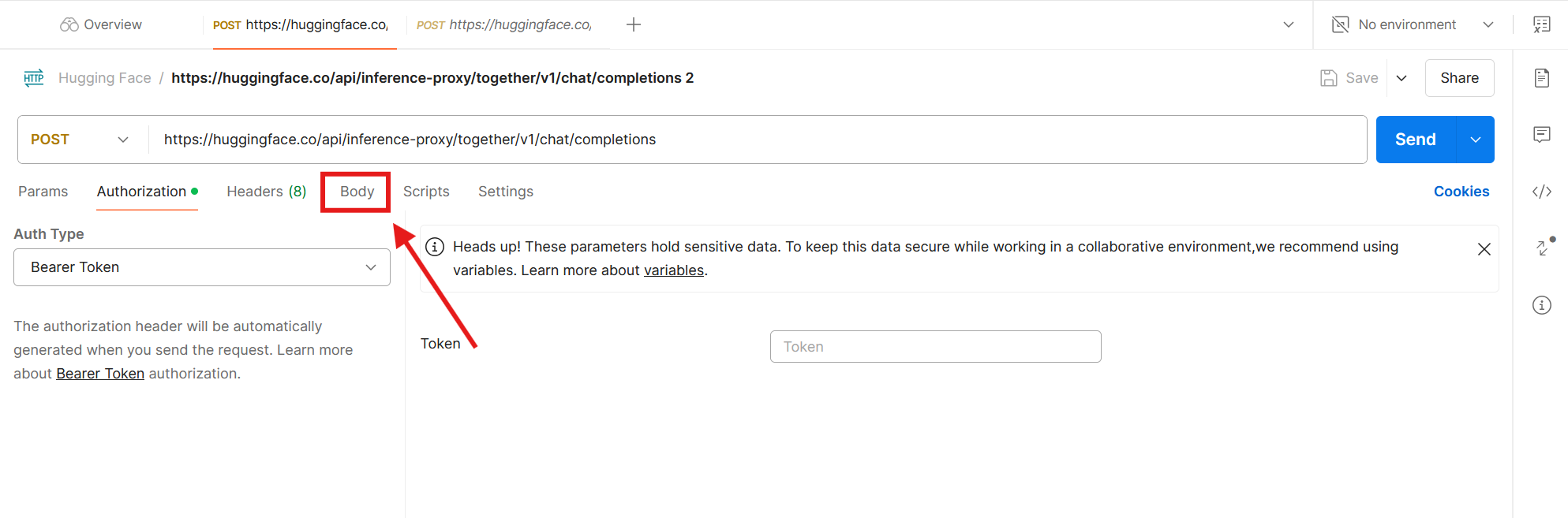
Click the raw radio button and paste only the content inside the data flag:







{
"model": "deepseek-ai/DeepSeek-R1",
"messages": [
{
"role": "user",
"content": "What is the capital of France?"
}
],
"max_tokens": 500,
"stream": false
}
Note: When copying from cURL requests directly, don't paste in --data or the single quote marks at the start and ending of the body—notice that I've removed them in the snippet above.

9. You're ready to call the Hugging Face API with Postman. Click the Send button on the right side of the screen.

If you've followed all the steps so far, you'll see an HTTP 200 OK status with the answer to your message.

Any time you want to send a different prompt, edit the value of the "content" key and click the Send button.

Want to set up more advanced functionality? Read the Hugging Face Serverless Inference API documentation to learn more.
Connect Hugging Face to your other apps
Let's get the bad news out of the way: technical skills are required to use everything Hugging Face has to offer.
But you can use Zapier's Hugging Face integration to send and retrieve data from models hosted at Hugging Face, with no code involved at all. Learn more about how to automate Hugging Face with Zapier, or try one of these popular workflows people are setting up right now.
Track email information in Google Sheets with Hugging Face
Instantly organize Typeform entries in Google Sheets with Hugging Face
Translate Help Scout conversations with Hugging Face
Zapier is the most connected AI orchestration platform—integrating with thousands of apps from partners like Google, Salesforce, and Microsoft. Use forms, data tables, and logic to build secure, automated, AI-powered systems for your business-critical workflows across your organization's technology stack. Learn more.
AI models at your fingertips
If you have technical expertise in the field of AI and machine learning, Hugging Face is a great toolbox to speed up work and research, without you having to worry about the hardware side of things.
But if you're like me, Hugging Face is still a great place to try out new models, expand your horizons, and add a few AI tools to your work toolkit. And who knows, if the platform evolves to offering a no-code approach to machine learning, maybe then we'll all get to play with the big kids.
Related reading:
This article was originally published in May 2023. The most recent update was in March 2025.







