Vector embeddings help make it possible to connect AI responses to your actual data. I became interested in them after learning about how they're involved in retrieval augmented generation (RAG), which can help offer additional context and reduce hallucinations in AI.
So what is vector embedding? It's simple: a multidimensional process for turning data points into vectors that capture semantic context by encoding data relationships.
Ok, it's not simple. But stick with me—I'll break it down and explain it like you've never met an AI. Because while it takes effort to generate embeddings, the payoff is worth it.
Table of contents:
What are vector embeddings?
Vector embeddings are a way of turning data, like the pages on your website, into numbers so a computer can understand how they're related.
The point of vectorizing data is to make it searchable by meaning across a bunch of different dimensions, not just keywords. You can visualize the concept by checking out the sample dataset in the TensorFlow Embedding Projector.

Consider this overly simplified example for why this all matters.
You're looking for a new recommendation based on your favorite movie. To get an accurate recommendation, you need to capture all sorts of data points associated with each movie—genre, themes, directorial style, time period, tone, and so on—something vector embeddings do by positioning entities in a multidimensional space.
So even if you're new to vector embeddings, you're not really new to the concept. It's how a lot of recommendation algorithms work, and if you've done a Google search any time in the past decade, you know that it always knows what you're looking for—across many dimensions—no matter how you phrase it.
Search for broad concepts in the TensorFlow Embedding Projector to explore how this demo dataset maps relationships using vector embeddings.

How does vector embedding work?
Let's say I want to analyze the content on my website—that's the reason I started using vector embeddings, actually. I can use a tool like Screaming Frog to crawl the site and extract the data, then connect it to OpenAI (or another large language model) to generate vector embeddings for each page. I've also done this using Google Colab—the key piece is connecting to an LLM using an API key to generate the embeddings.

The AI model captures the meaning of each page, based on patterns it knows from its training.
AI is doing the heavy lifting here to turn the data into vector embeddings. Its incredible pattern-recognition abilities make it possible to find complex patterns and relationships and then encode those into numbers. That's what makes vector embeddings so powerful for things like search and retrieval.
To put it in perspective: embeddings map your data into a high-dimensional space—often with hundreds or thousands of dimensions, depending on the model used. That high-dimensional representation lets the model understand context and meaning—like distinguishing between "Apple" the company and "apple" the fruit and "Apple" the child of Gwenyth Paltrow.
Trying to manually define and compare all those relationships across a dataset would be impossible. The best you could do, even with the help of non-AI technology, would be approximation. AI is making meaning out of massive, messy data.
How to generate vector embeddings
This all sounds super complicated—like something that developers can do but the rest of us can't. But I'm proof that anyone can make it happen.
Creating a full working RAG model with vector embeddings is outside the scope of what I'm walking you through here, but I do want to give you a path to get started.
Step 1: Pick your data source
The process for creating a RAG model using vector embeddings depends on the data source, so make sure you know what data you're trying to grab. I've successfully built a few RAG models as a non-developer with the following data sources:
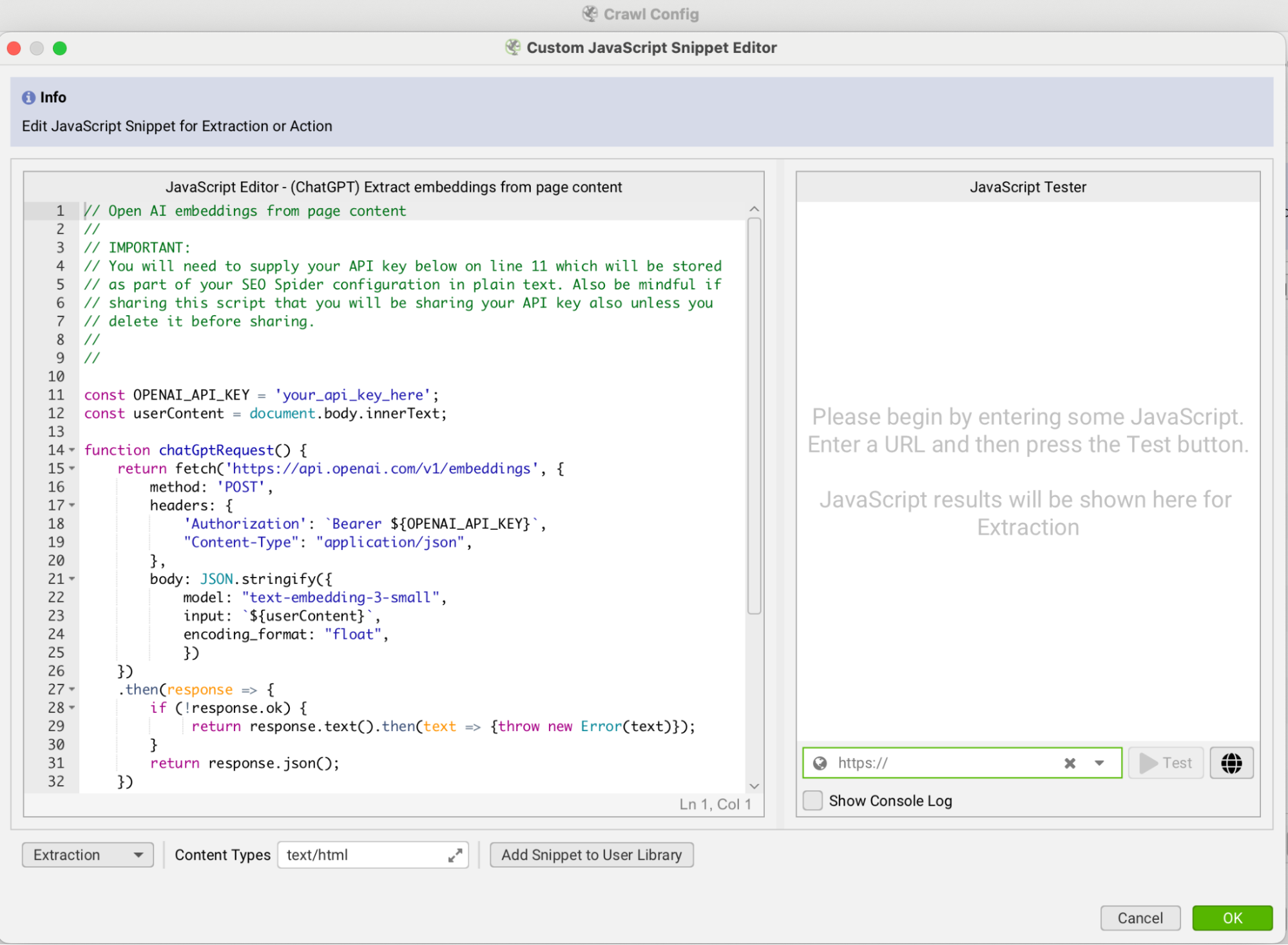
Screaming Frog website crawl. After crawling with Screaming Frog, I processed the results by calling the OpenAI API to generate embeddings. Read more about how this works.
Airtable database. I used the data in my Airtable CRM to build a sales assistant that doesn't require logging in and tracking down specific records every time I need information.
Google Drive and Google Docs data. I used Drive as a data source so I could use my past content as a standard for creating new content.
Step 2: Decide where to store vector embeddings
You'll need a place to store your vector embeddings: a vector database.
The information you pass to a vector database (and related metadata) is stored in an index, which is what will be queried for information retrieval once you have your RAG model all set up.
For getting started, I'd recommend one of these options:
Pinecone. Pinecone is a hosted vector database with a solid free plan. This is what I've been using.
Chroma. Chroma has a free option you can run on your local machine, so it's good for personal RAGs.
Just remember that whoever has access to your database—directly or through a user interface you've built over it—potentially has access to every detail within the data you've uploaded.
Step 3: Use an AI chatbot as your initial copilot developer
I always start by using ChatGPT to help me vibe code. I provide a lot of information about what I'm trying to accomplish and tell it which tools I'd like to use to get there (or get recommendations if I'm not sure what to use yet).
For example, when I asked for help creating a RAG model for my Airtable CRM data, ChatGPT helped me identify that I'd need an Airtable API key and told me where to get it. It also helped me narrow down to tools like Pinecone and Chroma as potential vector databases.

Step 4: Build and test in Google Colab
There are tons of ways to go about building a RAG model with vector embeddings. I've been defaulting to Google Colab, and it's been working great for this use case.
Work with ChatGPT to help develop Colab code blocks (or use the built-in Gemini assistant), add your sources (your data source and vector database destination), and run the code to test it out.

Your code will need steps to (1) access the data, (2) vectorize the data, (3) store the data in a vector database, and (4) test retrieval with a prompt.
Step 5: Build an interface over your RAG model
Working in Google Colab is great for building and testing—less so when you want to use your solution over the long term.
I adapted my Colab notebook code for use in AI coding tool Replit and added the necessary credentials to connect to my Pinecone database. After doing this a few times, I can now create a working UI with just a few prompts.

Learn more about vector embeddings
Here are some of the resources I've consulted to help me understand these concepts and use vector embeddings in my workflows:
Vector Embeddings Is All You Need by Mike King: This article is a comprehensive resource about how vector embeddings work at a technical level. It's especially useful if you want to understand how embeddings connect to semantic SEO strategies.
How I Found Internal Linking Opportunities with Vector Embeddings by Everett Sizemore: Practical applications for vector embeddings in SEO teams, detailing exact steps for using embeddings to discover internal link opportunities.
You don't need to be technical to use vector embeddings—just be willing to experiment.
Related reading: