
If regular AI models are an overeager junior coworker who always runs with their first idea no matter how bad it is, reasoning models (large language models with reasoning abilities) are experienced executive assistants who slow down and consider their options. They take time to "think" through tougher problems. They're not a replacement for regular models, but they can be very powerful when used right.
OpenAI's o1 and o1-mini models were the first reasoning models released to the public. Just a few months later, we already have o3-mini, and o3 is in the pipeline.
Other companies have also started to release their own reasoning models: DeepSeek has R1 and Google has Gemini 2.0 Flash Thinking, while both Anthropic's Claude 3.7 Sonnet and xAI's Grok 3 have built-in thinking modes.
Since it's only a matter of time before there's more, let's step back and look at what reasoning models are, how they're different from other LLMs, and what they're good for.
But first, a quick apology. It's really difficult to write about LLMs, let alone reasoning models, without some degree of anthropomorphization. I'm not a good enough writer to avoid it, but just remember we're talking about very advanced computer code. When I say a model is thinking, wants to do something, or attribute any other kind of human action or emotion to it, I'm using an easy shorthand to describe what's going on inside an incredibly complicated and poorly understood app. It's important to remember that, or you could really make a fool of yourself.
Table of contents:
What are reasoning models?
Every reasoning model starts out as a regular large language model (LLM).
OpenAI's o1 model is based on GPT-4o, DeepSeek-R1 is based on DeepSeek-V3, and Gemini 2.0 Flash Thinking is based on Gemini 2.0 Flash. Anthropic and xAI haven't even bothered to come up with new names: Claude 3.7 Sonnet and Grok 3 are regular models that can also think. (For what it's worth, this is most likely to be the approach that wins out; OpenAI is already talking about GPT-5 combining the features of GPT-4.5 and o3.)
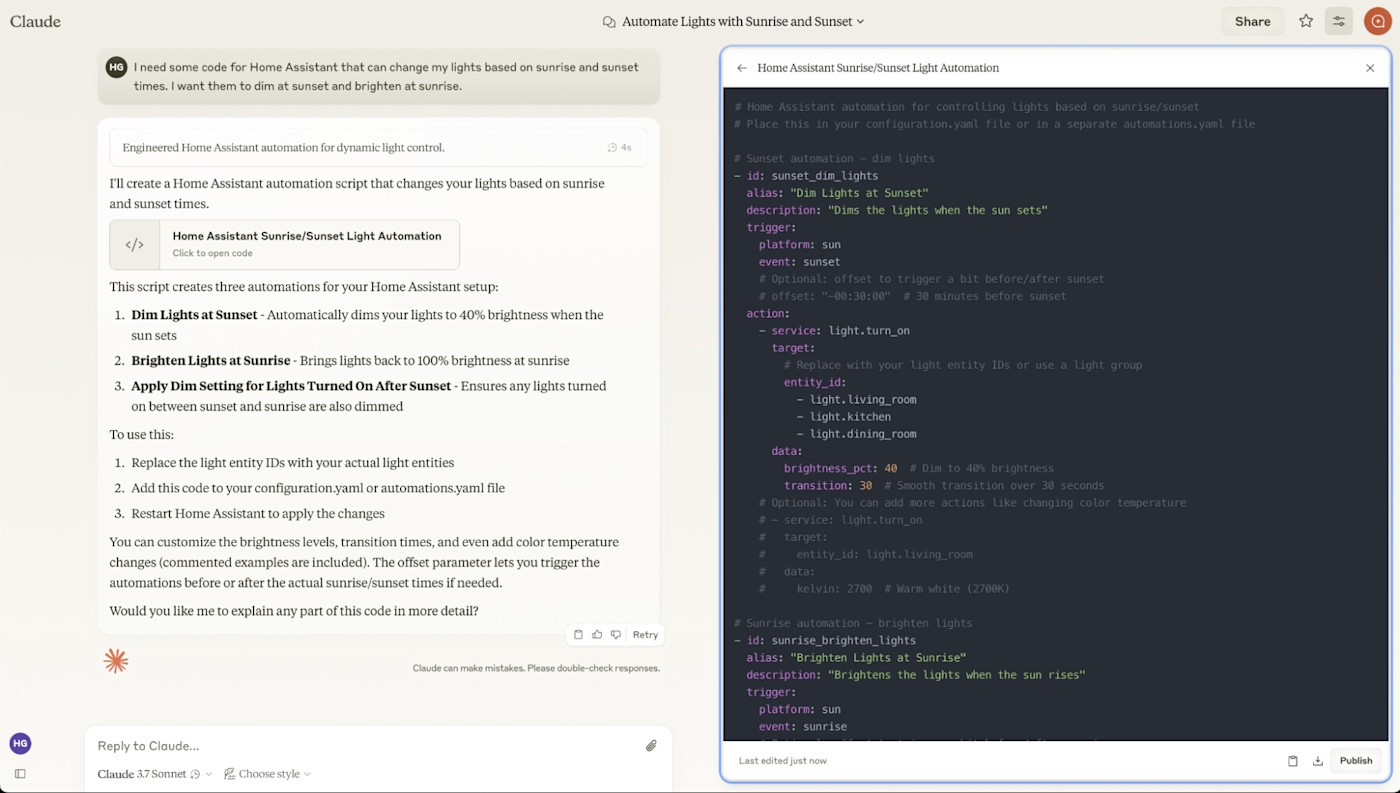
All these reasoning models are LLMs that are trained to think through prompts more and reason through problems, instead of just answering with the most obvious answer based on its training.
How do reasoning models work?
Every reasoning model still relies on transformers, attention, neural networks, pre-training, and all the other technological advancements that have made AI actually useful. If you're not familiar with those concepts, check out how ChatGPT works for a deeper dive—though it's not really necessary if you just want to understand the basics of reasoning models.
The most important thing to know is that LLMs are supercharged autocomplete engines. There's lots of work done to abstract away this fact and make them significantly more useful, but in the most stripped down sense, if you give an LLM the prompt "Who wears short shorts?" it's really going to want to reply "We wear short shorts."
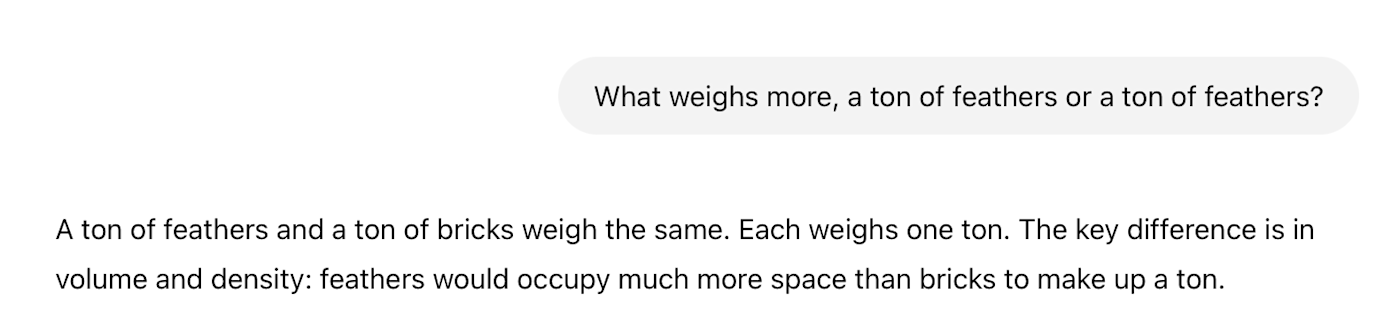
This tendency for LLMs to regurgitate their training material is the basis of the New York Times' lawsuit against OpenAI, but it's also responsible for a huge amount of AI errors and hallucinations. For the longest time, if you asked an LLM, "What weighs more, a ton of feathers or a ton of feathers?" it would confidently reply that a ton of feathers and a ton of bricks weighed the same.
A prompt engineering technique called Chain of Thought (CoT) reasoning was used to get around this. The idea was that, by telling the AI to "think step by step" or prompting it to respond with how it generated its answer, it wouldn't just reply with the most obvious possible response; instead, it would fully consider the instructions. Shockingly, it actually worked really well.

Reasoning models are doing this same thing—they work by taking the base model and training it with reinforcement learning to respond to everything with CoT reasoning. When you ask a question, it'll say something like "Reasoning..." while it thinks. Then, once it answers, it'll tell you how long it thought for and give you the answer.
It's still doing CoT reasoning, but it's hiding the chain of thought from the user. In the image below, you can see how the chatbot told me it "reasoned" for 1 minute and 15 seconds, but it keeps the details of the reasoning behind a collapsible section.
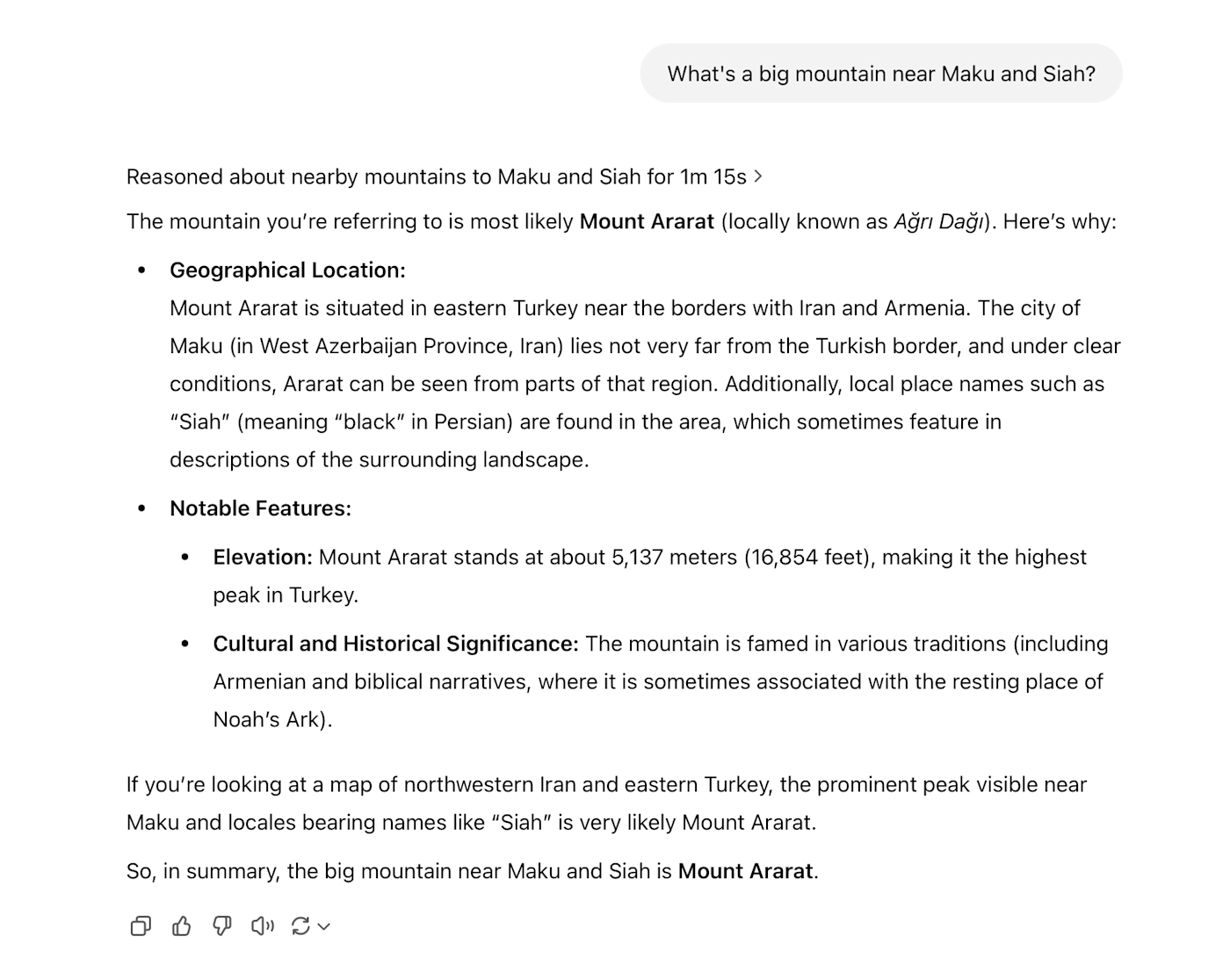
When you open the collapsible, it lists the steps it's taking—it's just summarizing the CoT.

Of course, when you ask an AI to solve a puzzle or generate some code, you don't want to have to read through hundreds of superfluous words as it thinks through the prompt. Instead, reasoning models hide the chain of thought process and give you a handy summary at the end.
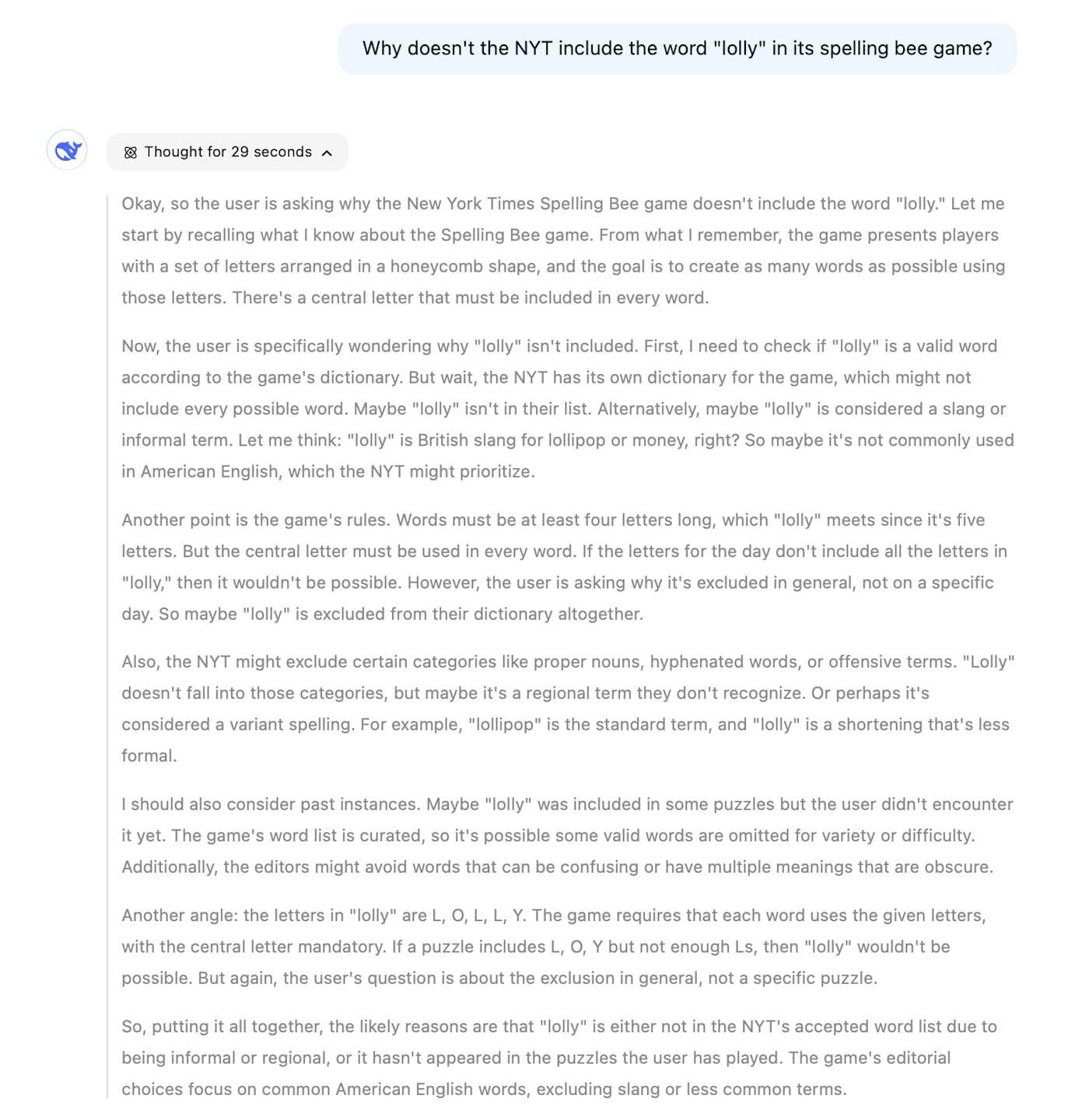
This also highlights another quirk of reasoning models. The longer the chain of thought they develop, the more likely they are to reach the correct answer. Of course, generating a longer chain of thought takes more computing resources and thus costs more money, so there's always a tradeoff. That's why o3-mini is available with low, medium, and high levels of reasoning effort.
How are reasoning models different from regular LLMs?
Reasoning models are much better than regular LLMs when it comes to tasks that require logical reasoning, math, science, and coding. Their ability to process things step by step also makes them more useful for autonomous features, like ChatGPT's Deep Research.
In the image below, you can see that the five highest performing models on Artificial Analysis are all reasoning models.
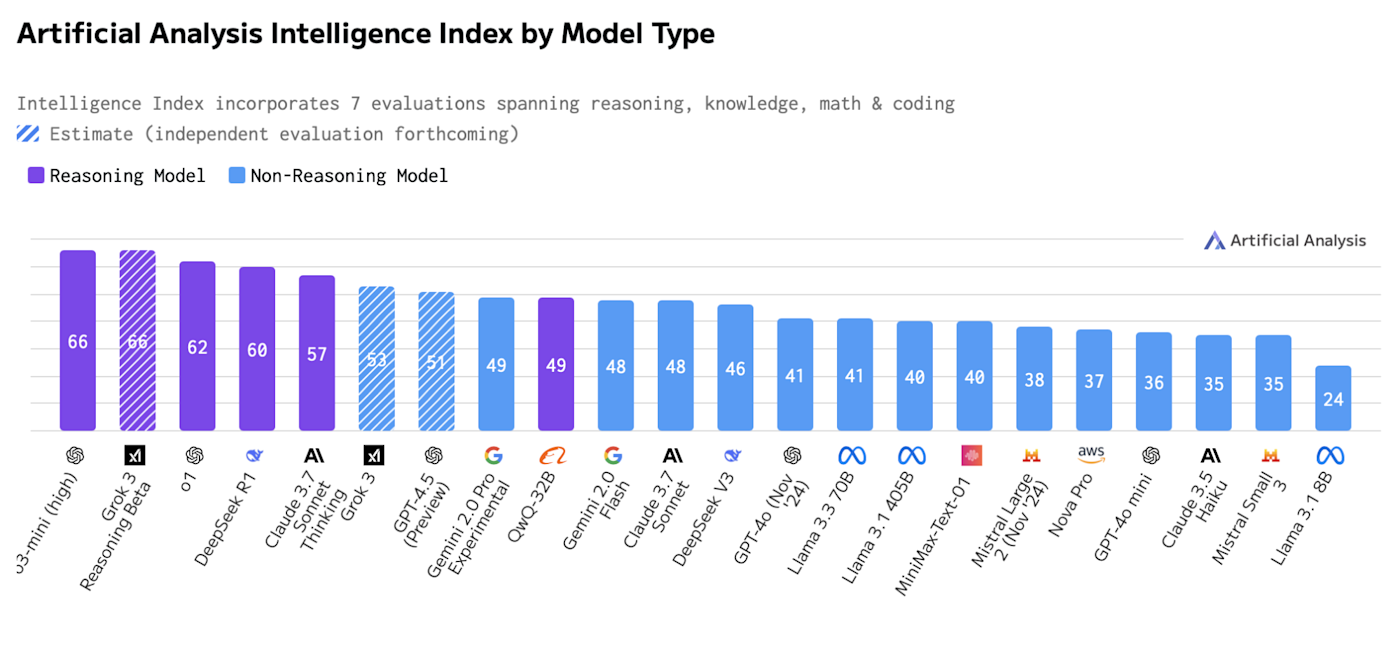
But reasoning models are much slower than regular models. It takes time for them to work through a chain of thought. A typical reasoning query on ChatGPT can take two or three minutes.
And for more general tasks like writing emails, brainstorming, and anything that doesn't require complex reasoning, the performance differences are a lot less clear-cut. Chatbot Arena compares LLMs head-to-head, and you can see that the top models in its current leaderboard are a mix of regular models, regular models with optional reasoning capabilities, and reasoning models.
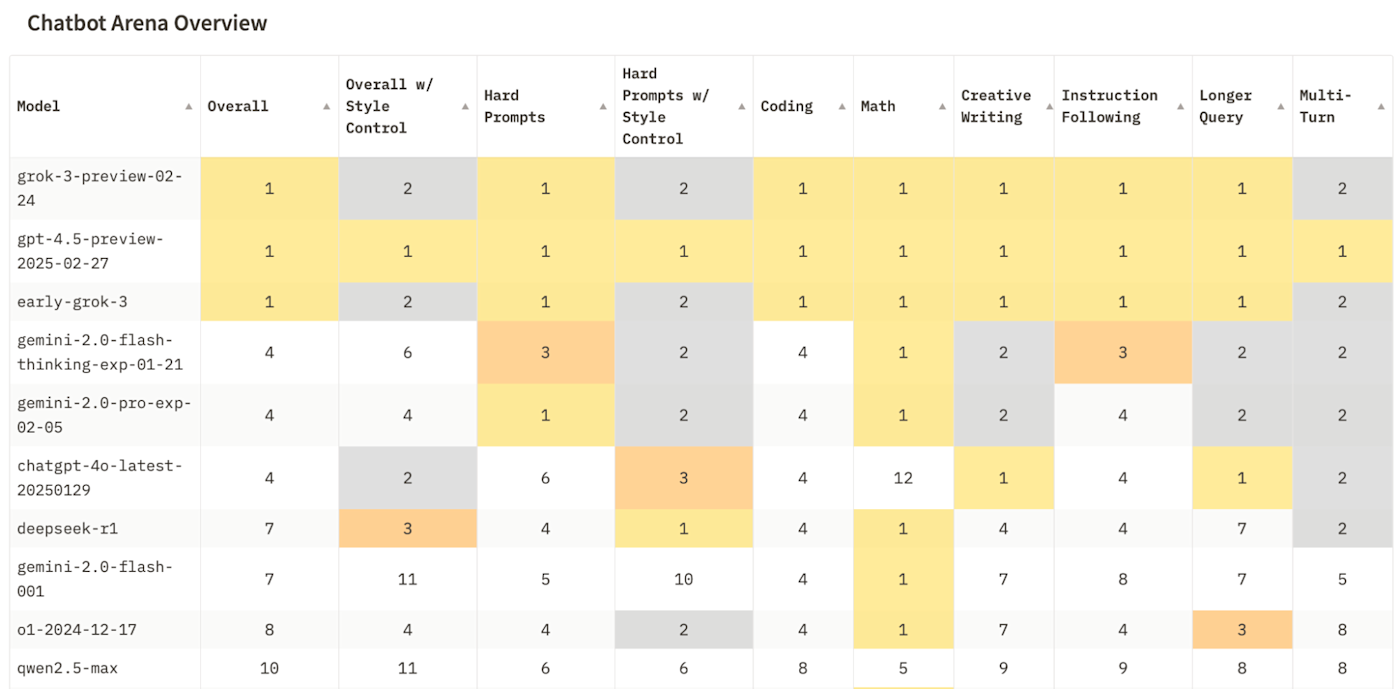
Reasoning models are relatively new and, as a result, typically lack multimodal features. Some can handle images, but they don't have the kinds of live audio and video features that, for example, GPT-4o provides through Advanced Voice Mode.
Since reasoning models typically cost far more to run than regular models (or limit you to a certain number of prompts per month), there are plenty of times when using a regular model will get you the same results, faster and for less.
This is why I think combined models like Sonnet 3.7 are the way forward, especially if they reach the point where they assess the prompt and are able to decide when something needs reasoning and when it doesn't.
Add AI automation to your workflows
As AI models become more powerful with tools like reasoning, you can delegate even more work to them so you can focus on the human side of things. Learn more about how Zapier can add AI automation to your work, letting you build custom solutions that scale across your entire organization.
Related reading:









